Hyperscan: high-performance multiple regex matching library
Hyperscan is a high-performance regular expression matching library from Intel. It is based on the X86 platform based on PCRE prototype development. While supporting most of the syntax of PCRE, Hyperscan adds specific syntax and working modes to ensure its usefulness in real-world network scenarios.
1. 概述
Hyperscan demo中使用libpcap从pcap文件中读取数据包,并根据一个规则文件中指定的多个正则表达式对报文进行匹配,并输出匹配结果和一些统计信息。Hyperscan增加了特定的语法和工作模式来保证其在真实网络场景下的实用性。与此同时,大量高效算法及IntelSIMD*指令的使用实现了Hyperscan的高性能匹配。
2. KeyWords & KeyFunc
- Patterns: 规则,用来匹配关键词的规则,支持PCRE的大部分语法(正则表达式c十六进制.etc)
- id: 与规则绑定,一个规则对应一个不同的id,匹配命中时返回pattern对应的id
- flags: 与规则绑定,对pattern进行特殊操作,如:与或非逻辑运算(绑定多个pattern),忽略大小写,多行匹配,单次匹配.etc
- hs_compile_*(): 将patterns生成无向连通图(database),匹配时把数据往连通图里迭代遍历
- Scratch():在扫描数据时,Hyperscan需要少量的临时内存来存储动态内部数据。但database的数量太大了,无法装入堆栈,特别是对于嵌入式应用程序,而且动态分配内存过于昂贵,因此必须为扫描函数提供预先分配的“Scratch”空间。
- Serialization(): 将生成的database序列化成二进制文件,再由凡序列化拿到databse。
- Scan(): 匹配,将需要匹配的数据放入database无向连通图中匹配,命中后调用回调函数。
3. 原理
Hyperscan以自动机理论为基础,其工作流程主要分成两个部分:编译期(compiletime)和运行期(run-time)。
3.1编译期
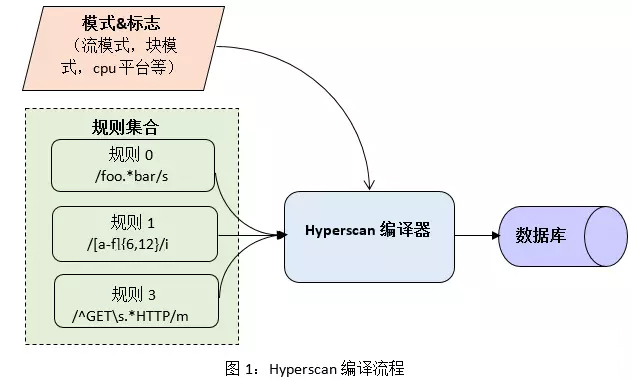
Hyperscan 自带C++编写的正则表达式编译器。如图1所示,它将正则表达式作为输入,针对不同的平台,用户定义的模式及特殊语法,经过复杂的图分析及优化过程,生成对应的数据库。另外,生成的数据库可以被序列化后保存在内存中,以供运行期提取使用。
3.2运行期
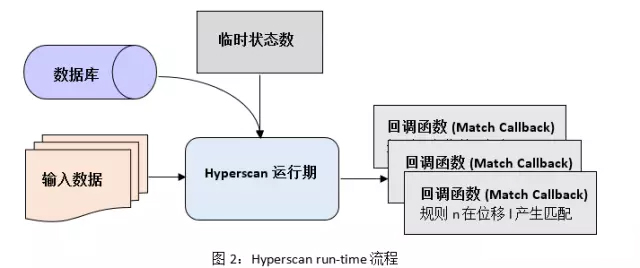
Hyperscan的运行期是通过C语言来开发的。图2展示了Hyperscan在运行期的主要流程。用户需要预先分配一段内存来存储临时匹配状态信息,之后利用编译生成的数据库调用Hyperscan内部的匹配引擎(NFA, DFA等)来对输入进行模式匹配。Hyperscan在引擎中使用Intel处理器所具有的SIMD指令进行加速。同时,用户可以通过回调函数来自定义匹配发生后采取的行为。由于生成的数据库是只读的,用户可以在多个CPU核或多线程场景下共享数据库来提升匹配扩展性。
4. Hyperscan伪代码
4.1 编译
函数buildDatabase用来编译规则文件中的多个正则表达式,参数mode指定了是BLOCK,STREAM,或者向量模式。
static hs_database_t *buildDatabase(const vector<const char *> &expressions,
const vector<unsigned> flags,
const vector<unsigned> ids,
unsigned int mode) {
hs_database_t *db;
hs_compile_error_t *compileErr;
hs_error_t err;
Clock clock;
clock.start();
err = hs_compile_multi(expressions.data(), flags.data(), ids.data(),
expressions.size(), mode, nullptr, &db, &compileErr);
clock.stop();
if (err != HS_SUCCESS) {
if (compileErr->expression < 0) {
// The error does not refer to a particular expression.
cerr << "ERROR: " << compileErr->message << endl;
} else {
cerr << "ERROR: Pattern '" << expressions[compileErr->expression]
<< "' failed compilation with error: " << compileErr->message
<< endl;
}
// As the compileErr pointer points to dynamically allocated memory, if
// we get an error, we must be sure to release it. This is not
// necessary when no error is detected.
hs_free_compile_error(compileErr);
exit(-1);
}
//...
}其中的核心代码是hs_compile_multi的调用,此函数用来编译多个正则表达式,从代码可见除了mode参数,BLOCK和STREAM模式都使用这一API。它的原型是
hs_error_t hs_compile_multi(const char *const * expressions,
const unsigned int * flags,
const unsigned int * ids,
unsigned int elements,
unsigned int mode,
const hs_platform_info_t * platform,
hs_database_t ** db,
hs_compile_error_t ** error)其中,expressions是多个正则表达式字符串,flags和ids分别是expressions对应的flag和id数组;elements是表达式字符串的个数;其余参数与上一个例子中提到的hs_compile的参数涵义相同。
这里要注意的一个事情是参数ids,它是正则表达式的ID数组。每个表达式都有一个唯一ID,这样命中的时候匹配回调函数可以得到此ID,告诉调用者哪个表达式命中了。如果ids传入NULL,则所有表达式的ID都为0。
4.2 准备匹配临时数据
为接下来的匹配分配足够的临时数据空间(scratch space)
public:
Benchmark(const hs_database_t *streaming, const hs_database_t *block)
: db_streaming(streaming), db_block(block), scratch(nullptr),
matchCount(0) {
// Allocate enough scratch space to handle either streaming or block
// mode, so we only need the one scratch region.
hs_error_t err = hs_alloc_scratch(db_streaming, &scratch);
if (err != HS_SUCCESS) {
cerr << "ERROR: could not allocate scratch space. Exiting." << endl;
exit(-1);
}
// This second call will increase the scratch size if more is required
// for block mode.
err = hs_alloc_scratch(db_block, &scratch);
if (err != HS_SUCCESS) {
cerr << "ERROR: could not allocate scratch space. Exiting." << endl;
exit(-1);
}
}4.3 匹配
4.3.1 BLOCK模式
// Scan each packet (in the ordering given in the PCAP file) through
// Hyperscan using the block-mode interface.
void scanBlock() {
for (size_t i = 0; i != packets.size(); ++i) {
const std::string &pkt = packets[i];
hs_error_t err = hs_scan(db_block, pkt.c_str(), pkt.length(), 0,
scratch, onMatch, &matchCount);
if (err != HS_SUCCESS) {
cerr << "ERROR: Unable to scan packet. Exiting." << endl;
exit(-1);
}
}
}其中,db就是上一步编译的databas;data和length分别是要匹配的数据和数据长度;flags用来在未来版本中控制函数行为,目前未使用;scratch是匹配时要用的临时数据,之前已经分配好;onEvent非常关键,即匹配时调用的回调函数,由用户指定;context是用户自定义指针。
4.3.2 匹配回调函数
匹配回调函数的原型是
typedef (* match_event_handler)(unsigned int id,
unsigned long long from,
unsigned long long to,
unsigned int flags,
void *context)其中,id是命中的正则表达式的ID,对于使用hs_compile编译的唯一表达式来说,此值为0;如果在编译时指定了相关模式选项(hs_compile中的mode参数),则此值将会设为匹配特征的起始位置,否则会设为0;to是命中数据的下一个字节的偏移;flags目前未用;context是用户自定义指针。
返回值为非0表示停止匹配,否则继续;在匹配的过程中,每次命中时都将同步调用匹配回调函数,直到匹配结束。
4.4 清理资源
包括关闭流(hs_close_stream)、释放database等。